
13- Banco de Dados Relacional

- Published on
- /12 mins read
ACID
ATOMATICIDADE→ Controle sobre inicio e fim da transação, é a garantia que todo o bloco de transações foi executado integralmente
CONSISTENCIA→ Está ligada a essas informações serem coerentes e representarem bem a realidade
ISOLAMENTO→ É a separação das modificações de recursos ou de dados feitas por transações diferentes.
DURABILIDADE→ Preservação dos dados após as operações terem sido realizadas.
SQL - Structured Query Language.
Conceitos Básicos e Estrutura do Banco de Dados Relacional
DQL: Data query Language ou Linguagem de consulta de dados EX:SELECT
DML: Data manipulation language ou Linguagem de manipulação de dados EX:INSERT, UPDATE E DELETE
DDL: Data definition language ou lingugagem de Definição de dados EX:CREATE ALTER, DROP
Modelagem de Bancos de Dados
MER: modelo Entidade-Relacionamento.
DER: Diagramas Entidade-Relacionamento.
Cardinalidades:
1..1: (um para um) → Não tem necessidade de mais tabelas.
1..n ou 1..*: (um para muitos) → o lado que tem muitos recebe o um como chave estrangeira.
**n..n ou ..: (muito para muitos) → cria-se uma nova tabela com as Chaves-Primarias de Cada Tabela.
Ex:
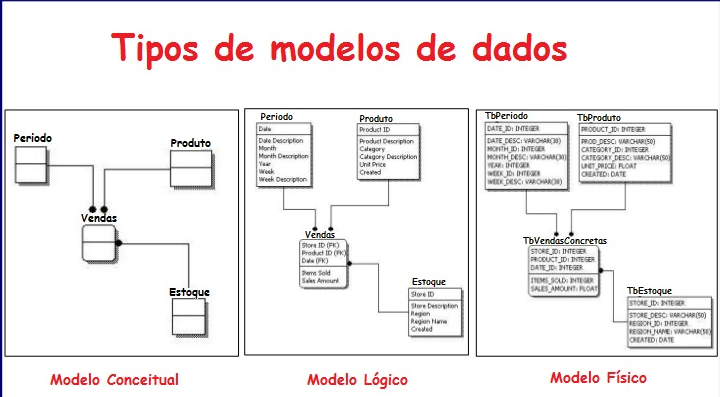
Modelagem Conceitual:
Modelagem Logica:
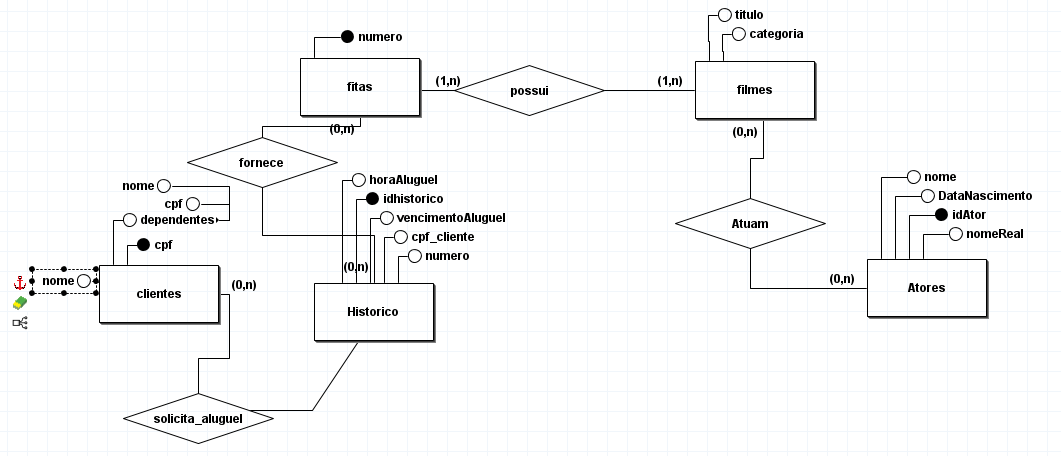
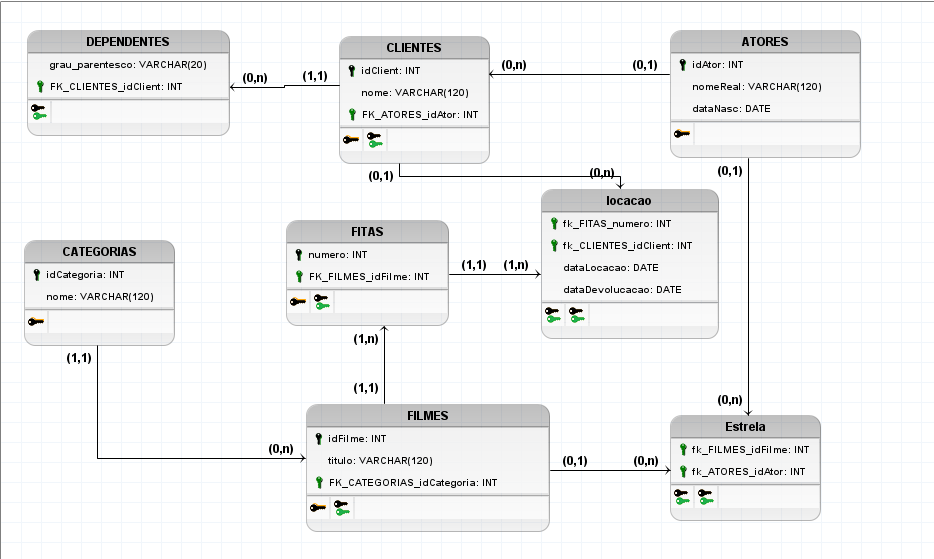
Modelagem Física
-- CREATE DATABASE locadora_de_fitas
-- Tabelas Primarias (Chave primaria)
CREATE TABLE ATORES (
idAtor SERIAL PRIMARY KEY NOT NULL,
nomeReal VARCHAR(120) NOT NULL,
dataNasc DATE NOT NULL
);
CREATE TABLE CATEGORIAS (
idCategoria SERIAL PRIMARY KEY NOT NULL,
nome VARCHAR(120) NOT NULL
);
-- Tabelas Secundaria(Chave primaria e estrangeira)
CREATE TABLE CLIENTES (
idClient SERIAL PRIMARY KEY NOT NULL,
nome VARCHAR(120) NOT NULL,
idAtor INTEGER NOT NULL,
FOREIGN KEY (idAtor) REFERENCES ATORES (idAtor)
);
CREATE TABLE DEPENDENTES (
idClient INTEGER PRIMARY KEY NOT NULL ,
grau_parentesco VARCHAR(20) NOT NULL,
FOREIGN KEY (idClient) REFERENCES CLIENTES (idClient)
);
CREATE TABLE FILMES (
idFilme SERIAL PRIMARY KEY NOT NULL,
titulo VARCHAR(120) NOT NULL,
idCategoria INTEGER NOT NULL,
FOREIGN KEY (idCategoria) REFERENCES CATEGORIAS (idCategoria)
);
CREATE TABLE FITAS (
idFilme SERIAL PRIMARY KEY NOT NULL,
numero INTEGER NOT NULL,
FOREIGN KEY (idFilme) REFERENCES FILMES (idFilme)
);
CREATE TABLE ESTRELA (
idFilme INTEGER PRIMARY KEY NOT NULL,
idAtor INTEGER NOT NULL,
FOREIGN KEY (idFilme) REFERENCES FILMES (idFilme),
FOREIGN KEY (idAtor) REFERENCES ATORES (idAtor)
);
CREATE TABLE LOCACAO (
numero INTEGER PRIMARY KEY NOT NULL,
idClient INTEGER NOT NULL,
dataLocacao DATE NOT NULL,
dataDevolucacao DATE NOT NULL,
FOREIGN KEY (idClient) REFERENCES CLIENTES (idClient)
FOREIGN KEY (numero) REFERENCES FITAS (numero)
);Configuração do Ambiente:
Postgress; MariaDB;
Tipos de dados e custo de armazenamento
- Tabelas, Colunas e Registros
Tabelas: O banco de dados e organizado por tabelas que possuem linha e colunas, cada tabela precisa-se ter um nome único e uma chave-Única para identificar cada linha.
Colunas: Representar um atributo especifico que guardam um tipo de dado especifico: texto, numero, data entre outros.
Registro: São os dados dentro da tabela.
Restrições de Valor:
NOT NULL → Valor não pode ser nulo UNIQUE → Valor tem que ser unico DEFAULT → Define um valor padrão se não for passado valor algum
Chaves-Primarias e Estrangeiras
Primaria → Valor unico na tabela, ele que pode indentificar o registro. ex: CPF, id.
Estrangeira → Chave primaria de outra tabela para futuros relacionamento entre tabelas.
| Tipos de dados | Dentro do SQL |
|---|---|
| Texto | TEXT |
| Inteiros | INTEGER/INT |
| Decimal/Numerico | Decimal/ Numeric |
| Caractere/Varchar | Character/Varchar |
| Data/Hora | Data/Time |
| Booleano | Boolean |
Auto Incremento→ Informações que incremente automaticamente ex: POSTGRES=SERIAL(Comando começa em 1 e incremente +1 para cada adição de um novo registro)
phpMyAdmin=AUTO_INCREMENT.
Criar uma Tabela
-- Como criar uma Tabela
CREATE TABLE NomeTabela{
id SERIAL NOT NULL,
nome VARCHAR(255) NOT NULL COMMENT "NOME",
data DATE COMMENT "DATA"
}--Como não criar uma tabela
CREATE TABLE NomeTabela{
id INTEGER,
nome TEXT,
data DATETIME --data e hora
}CRUD
Create → INSERT INTO
Read → SELECT
Update → UPDATE
Delete → DELETE
--CREATE
INSERT INTO nome_Tabela (colunaInt,colunaTexto02) VALUES (1,"valorcolunar2")
--Exemplos
-- PROJETOS
INSERT INTO PROJETOS (descricao, categorias) VALUES ('Projeto 1', 'Desenvolvimento, front-end, back-end, banco de dados');
-- CATEGORIAS
INSERT INTO CATEGORIAS (tipoProjeto, descricao, horasNecessarias) VALUES ('Banco de dados', 'Desenvolvimento de banco de dados', INTERVAL '46 hours');
-- FUNCIONARIO
INSERT INTO FUNCIONARIO (nome, funcao) VALUES ('João', 'Desenvolvedor');
-- CLEINTES
INSERT INTO CLIENTES (cpnj_cpf, investimento, nomeEmpresa) VALUES ('123456789', 10000.00, 'Empresa 1');
--Read
SELECT (informacoes vc quer) FROM (de que tabela?) WHERE (CONDIÇÕES) AND (JUNÇÃO)
-- 1 Retorna todo os projetos de um cliente
SELECT cl.idcliente ,ct.idprojetos, p.descricao, p.categorias FROM projetos p, clientes cl, contratos ct
WHERE cl.idcliente=3 AND ct.idcliente=cl.idcliente AND p.idprojetos=ct.idprojetos
--Update
INSERT INTO nome_Tabela SET (colunaInt=1,colunaTexto02="novo texto") WHERE colunaInt=1
-- o where e a condição para que seja um registro unico e não atualizar todos dados da tabela
--Delete
DELETE FROM nome_tabela WHERE colinaInt=1
-- o where e a condição para que seja deletado um unico registro e não deletar todos dados da tabela
Alterando e Excluindo Tabelas
Alter Table → Alterar informações da tabela ou excluir, modificar restrições, indices, renomear tabelas dentre outros.
Drop Table → Deleta a tabela 👿
--Alterar Tabela
ALTER TABLE nome_tabela RENAME novatabela;
-- Dependo do dado da coluna o comando pode ser diferente
ALTER TABLE nome_tabela MODIFY COLUMN colunaVAR150 VARCHAR(255);
--Deletar Tabela
DROP TABLE nome_tabela;Mudando informações Existente Cuidados
ON DELETE → Especifica o que acontecer com o registros dependentes quando um registro “PAI” e excluído.
ON UPDATE → Define o comportamento dos registros dependentes quando um registro “Pai” e alterado.
CASCADE →
SET NULL →
SET DEFAULT →
RESTRICT →
Normalização de dados
Inconsistência dos dados? como resolver isso e so Normalizar a entrada de dados.
Formular os dados que entram por exemplo: CPF e String ou int? Você vai dizer e adotar como padrão.
6FN → tem como objetivo eliminar a redundância
1FN → ATOMICIDADE DE DADOS
2FN → Todos atributos não chaves devem depender da Chave-Primaria.
3FN → Nenhum coluna que não e chave pode depender de outra coluna que não e Chave
UPDATE nometabela SET rua= SUBTRING_INDEX(SUBSTRING_INDEX(endereco, ',',1),',',-1);Consultas com junções e Sub Consultas
inner join,
left join
Right join
Full Join
Sub-Consultas
SELECT * FROM nomeTabela WHERE id NOT IN (SELECT id_coluna FROM tabela2);- Funções agregadas e agrupamento de resultados
- Índices
Funções Agregadas
COUNT → Conta o numero de registros
SUM → Soma os valores de uma coluna numerica
AVG → Calcula amedia dos valores de um coluna numerica
MIN → REtorna o valor minimo de uma coluna
MAX → Retorna o valor maximo de uma coluna
Agrupamento de Resultados
group by
Indices de Buscas
idx_index
Editando e removendo dados
Permissionamento e Views
Índices
View
CREATE VIEW
CREATE MATELIZE VIEWStored Procedures
Pode ser armazenados de forma compilada no catalogo do SGBD;
Procedures não retorna um valor para o usuario (função retorna valor para o usuario)
Procedures → Rotina para o SGBD não precisa retorna nada
Function → Rotina que retorna-ra uma valor para o usuario.
Salva em cache do banco
O codigo e armazenado na stored procedures no banco
Aumenta a manipulação de tipos de dados complexos usados pelos procedimentos
Aumenta a segurança por limitar o acesso de alguns usuarios ao BD
CallDesvantagem: Quando voce ultiliza mais de 1 SGBD,
Podem ser implementadas de varios modos; Lingugagens não-procedurais;
Procedurais → Seguem o padrão SQL/PSM(ISO Starndard);
Linguagens externas geralmente C++;
Implementação (lingugagem procedural)
SQL/PSM → Persistent Stored Modules
Cada SGBD ofere sua propria linguagem (Oracle Pl/SQL)
PostgreSQL → SPs não retornam valores, e plpgsql
PostgreSQL 11 introduziu o comando CREATE PROCEDURE com suporte a transações.
Diferança entre Funciton e Procedure
Funciton → Chamada parte de um query Select, não permite realizar commit ou rollback;
Procedure → Chamada de modo isolado usando call; Pode realizar commit ou rollback;
CREATE [OR REPLACE] PROCEDURE
name ([[argname] argtyoe[, ...]])
LANGUAGE plpgsql
AS &&
DECLARE
--Declaraçao variavel
BEGIN
--Corpo da stored procedure
END;
$$;
CALL procedure_name (params, 'Rua dos Corsarios 120', '47 99999-9999');--SQL
CREATE OR REPLACE PROCEDURE p_gravaEntregadores (a_nome VARCHAR(40)),
a_endereco VARCHAR(50), a_celular VARCHAR(50), a_celular VARCHAR(15))
LANGUAGE sql
AS $$
INSERT INTO funcionarios (funcionario, endereco, cargo,celular)
VALUES (a_nome, a_endereco, 'Entregador', a_celular);
END
$$;
--PLPGSQL
CREATE OR REPLACE PROCEDURE p_gravaEntregadores (a_nome VARCHAR(40)),
a_endereco VARCHAR(50), a_celular VARCHAR(50), a_celular VARCHAR(15))
LANGUAGE plpgsql
AS $$
BEGIN
INSERT INTO funcionarios (funcionario, endereco, cargo,celular)
VALUES (a_nome, a_endereco, 'Entregador', a_celular);
END
$$;CALL p_gravaEntregadores ('Bruno', 'Rua dos Corsarios 120', '47 99999-9999');Modo dos argumentos
| IN | (default) indica que o parâmetro e de entrada. |
|---|---|
| OUT | Indica que o parâmetro e de saída. Não permitido em procedures. |
| INOUT | Indica que o parâmetro e de entrada e saída. |
| VARIADIC | Um Array de um tipo de dado de entrada. Deve ser o ultimo argumento. ex: VARIADIC INTEGER[] |
CREATE OR REPLACE PROCEDURE p_gravaEntregadores (IN a_nome VARCHAR(40)),
a_endereco VARCHAR(50), a_celular VARCHAR(50), a_celular VARCHAR(15))
CREATE OR REPLACE PROCEDURE p_gravaEntregadores (OUT a_nome VARCHAR(40)),
a_endereco VARCHAR(50), a_celular VARCHAR(50), a_celular VARCHAR(15))
CREATE OR REPLACE PROCEDURE p_gravaEntregadores (INOUT a_nome VARCHAR(40)),
a_endereco VARCHAR(50), a_celular VARCHAR(50), a_celular VARCHAR(15))
CREATE OR REPLACE PROCEDURE p_gravaEntregadores (IN a_nome VARCHAR(40)),
a_endereco VARCHAR(50), a_celular VARCHAR(50), VARIADIC a_celular VARCHAR(15)[])Sobrescrever Chamada de Procedimentos(ou Funções)
CREATE OR REPLACE PROCEDURE p_soma (OUT a_va INTEGER, a_vb INTEGER),
LANGUAGE plpgsql
AS $$
DECLARE resultado INTEGER;
BEGIN
BEGIN
l_resultado = a_va+a_vb;
END
$$;
CREATE OR REPLACE PROCEDURE p_soma (OUT a_va INTEGER, a_vb INTEGER,
INOUT a_result INTEGER)
LANGUAGE plpgsql
AS $$
BEGIN
BEGIN
a_resul = a_va+a_vb;
END
$$;
CALL p_soma(1,2);
CALL p_soma(1,2, resultado_armazena);
Banco de Dados não Relacional
NOT Only SQL
Não seguem o modelo de tabelas e relacionamento( pode ser chave valor)
- Alto volume dad dados
- Alta escalabilidade.
- Alta Flexibilidade na estrutura de dados
- Tolerância a falhas.
Comumente utilizados onde o cenário de consistência imediata dos dados não e critica.
Tipos
- key-values
- Documentos
- Colunas
- Grafos
- …
Key-Value→ Armazenamento por chave valores
Exemplos: Redis, Riak, Amazon DynamoDB.
Document → Armazenam dados em documentos semiestrturados(JSON).
Exemplos: MongoDB, Counchbase, Apache, CouchDB.
Colunas → Armazenam em formato d colunas, permite alta escalabilidade e eficiencia em determinados tipos de consultas
Exemplos: Apache Cassandra, ScyllaDB, HBase
Grafo → Armazem e consultar dados interconectados, onde os relacionamentos entre os dados são tão importante quanto os proprios dados
Exemplos: Neo4j, Amazon Neptune, JanusGraph.
MongoDB
DataBase →
Coleção → Agrupamento de documentos, Não Existe uma estrutura de documento.
OBS: nome de coleção devem seguir algumas regras: devem começar com uma letra ou um underscore (_); Podem conter letras, números ou underscores; Não podem ser vazios; Não podem ter mais de 64 bytes de comprimento.
Documentos → São armazenados dem BSON(BINARY JSON), que são estruturas flexiveis e semiestruturadas; Cada documento possui um indentificador unico chamado _id; Composto por pares de chaves e valores.
OBS: Tamanho maximo de 16MB; Aninhamento de documentos; Flexibilidade na evolução do esquema;
TIPOS DE DADOS SIMPLES
| STRING | |
|---|---|
| NUMBER | |
| BOOLEAN | |
| DATE | |
| NULL | |
| OBJECTID |
Dados complexos → Arrays; Documento Embutido(Embedded Document); Referência, GeoJSON;
Estrutura do documento simples
{
_id: ObjectId(""),
"nome_campo":"valor_campo"
}Modelagem da estrutura do USUARIO e DESTINOS
jsonformatter.curiousconcept.com
{
"_id":1,
"nome": "Cleiton",
"idade": 23,
"data_nsc": "2000-05-24",
"enderecos":{
"numeros":231,
"cordenada": [-1.2312,1231.1231]
}
}Inner Documents
E comum com MONGOdb a denormalizar os dadospara evitar operações de junção(join) custosas.
{
"_id":1,
"nome": "Cleiton",
"idade": 23,
"data_nsc": "2000-05-24",
"enderecos":[
{
"numeros":231,
"cordenada": [-1.2312,1231.1231]
},
{
"numeros":232,
"cordenada": [-2.2312,1231.1231]
}
],
"parentes": [
{
"pai":"ObjectId(123)"
}
]
}Dados aninhados são específicos para o documento pai; Os dados aninhados são sempre acessados juntamente com o documento pai; A cardinalidade do relacionamento e um-para-muitos(parentes, enderecos);
Se os dados precisam ser consultado e atualizados independentemente do documento pai, e mais adaquedado ultilizar coleções separadas.
Comandos
db.usuarios
findOne({})
findOneAndUpdate({})
findOneAndDelete({})
find({})
UpdateOne({})
UpdateMany({})
deleteOne({})
deleteMany({})
Projeções → Definir quais campos devem ser retornados em uma consulta.
Ordenação → Ordenar os resutados de uma comnsulta com base em um ou mais campos.
Limitação → Limitar o numero de documentos retornados em uma consulta.
Paginação → find().skip(10).limit(5) → skip → quanto tempo e para esperar para travez a consulta → limit → Quanta consultas para travez
Operadores Lógicos
| Operador | Equivalente |
|---|---|
| $eq | == |
| $ne | != |
| $gt | > |
| $gte | >= |
| $it | < |
| $in | [] = Range |
| $nin | [] = !not |
| $and | |
| $or | |
| $not |
Sort → Orenação (asc, desc)
{idade: {$gt:18}}
{$or:{}}
....Redis
Sistema de armazenamento de dados em memoria de alto desempenho (resetou os servidor perdeu os dados 🕶️)
Características
- Armazenamento em memória.
- Estrutura de Dados Versátil
- Operações Atômicas
- Cache de Alto Desempenho
- Pub/Sub (Publicação/Assinatura)(Kafka raabitmq) simplista
Principais Comandos
SET → Adiciona uma informação
GET → Trazer a informação
DEL → Deletar a informação
EXISTS → Saber se existe pode voltar null(existe tempo de expiração dos dados)
KEYS → Trazer as chaves corresponde
INCR
DECR
set nome "Cleiton"
get nome
set nome1 "C"
keys nome*
del nome "Cleiton"
EXPIRE nome1 10 //10 segundos
TTL nome1 //tempo restante
DECR nome
LPUSH usuario "C" "A" "M" //Array
LRANGE usuario 0 -1
LPUSH usuario "z"Estrutura de Tabela no Dia a Dia
Otimização de Query
Conteúdo
- ACID
- SQL - Structured Query Language.
- Criar uma Tabela
- CRUD
- Alterando e Excluindo Tabelas
- Mudando informações Existente Cuidados
- Normalização de dados
- Consultas com junções e Sub Consultas
- Sub-Consultas
- Funções Agregadas
- Agrupamento de Resultados
- Indices de Buscas
- View
- Stored Procedures
- Sobrescrever Chamada de Procedimentos(ou Funções)
- Banco de Dados não Relacional
- Tipos
- MongoDB
- Modelagem da estrutura do USUARIO e DESTINOS
- Inner Documents
- Comandos
- Operadores Lógicos
- Redis
- Características
- Principais Comandos
- Estrutura de Tabela no Dia a Dia
- Otimização de Query